فشل Queue و Jobs في Laravel — كيف نتعامل معه بذكاء واحترافية؟
في عالم الـ Backend، الفشل ليس شيئًا غريبًا بل هو جزء طبيعي من أي نظام متكامل.
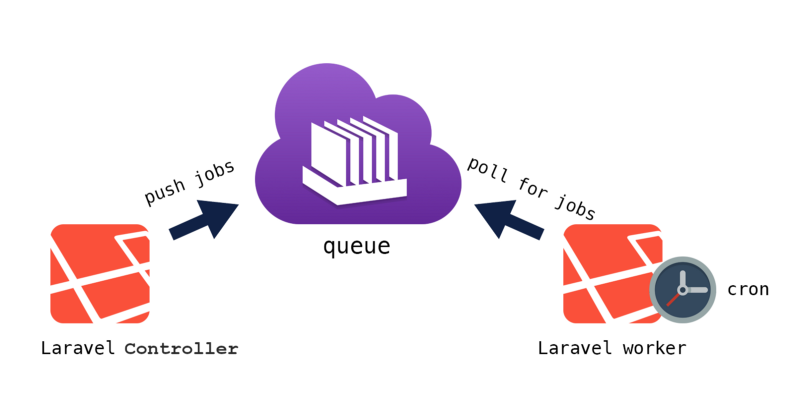
نظام الـ Queue في Laravel قوي جداً، ولكن الـ Jobs قد تفشل لأسباب مختلفة، مثل:
-
توقف خدمة خارجية (API)
-
ضغط أو ازدحام في قاعدة البيانات
-
أخطاء غير متوقعة في الكود
-
مشاكل الشبكة أو الاتصال
Laravel يوفر أدوات قوية للتعامل مع الفشل بطريقة ذكية ومنظمة. إليك أهم الآليات التي يجب معرفتها.
1. خاصية $tries: تحديد عدد محاولات التنفيذ
تحدد هذه الخاصية عدد المرات التي سيعيد Laravel فيها محاولة تنفيذ الـ Job قبل اعتباره فاشلاً:
بهذه الطريقة، إذا حدث فشل مؤقت مثل توقف API أو خطأ بسيط، ستتم إعادة المحاولة دون التأثير على النظام.
2. خاصية $backoff: فترة الانتظار بين المحاولات
تحدد المدة الزمنية التي يجب على Laravel انتظارها قبل إعادة محاولة تنفيذ الـ Job:
هذه الخاصية تساعد على:
-
منع الضغط على الـ API
-
تقليل الحمل على قاعدة البيانات
-
تجنب تجاوز الـ rate limit
وهي مفيدة خصوصًا مع الخدمات غير المستقرة.
3. دالة failed(): معالجة الفشل النهائي
عندما تفشل كل المحاولات، يقوم Laravel باستدعاء دالة failed() داخل الـ Job:
هذا يسهل تتبع الأخطاء وتنفيذ إجراءات احتياطية دون التأثير على المستخدم أو النظام.
نصائح إضافية مهمة
1. تسجيل الفشل في جدول failed_jobs
يمكنك تحليل الأخطاء لاحقًا ومعرفة الأسباب الجذرية للفشل.
2. استخدام Event: Queue::failing() لمراقبة الفشل على مستوى النظام
مثالي للمشاريع الكبيرة أو التي تعتمد على عمليات كثيرة في الخلفية.
3. افترض دائمًا أن أي Job قد يفشل
وصمم النظام بحيث يتعامل مع الفشل دون انهيار.
الخلاصة
يوفّر Laravel نظامًا مرنًا وذكيًا لإدارة فشل الـ Jobs. من خلال استخدام $tries و$backoff ودالة failed() والمراقبة المركزية، يمكنك بناء نظام متين قادر على التعامل مع الأخطاء واستعادة العمل بسهولة وكفاءة.